В самом начале давайте разберемся с новым для многих ppc специалистов термином. Букмарклет (от англ. bookmark — «закладка» и applet — «апплет») — это небольшой скрипт, оформленный как javascript URL и сохранённый в браузерных закладках. Его преимущество по отношению к расширениям в том, что он срабатывает только тогда, когда вы на него нажали и только в рамках выбранной вкладки, поэтому он не тормозит ваш браузер, не зависит от его типа и версии, безопасен.
С помощью апплетов можно в один клик:
- посмотреть dataLayer с его историей;
- скачать файл со всеми url(-ами) или ссылками на изображения, которые есть на странице;
- изучить сводку по самым часто встречающимся словам и сочетаниям слов на странице (понять, куда будет целиться автотаргетинг) и др.
Сам я встретился с ними в статьях по seo оптимизации от Андрея Антохина (автора tg канала «Hello, Digital World») и в каталоге Arsenkin Tools. Наши коллеги по работе с трафиком из поисковых систем написали уже десятки таких маленьких помощников для SEO нужд и мне стало как-то обидно, что для спецов по платному трафику нет ни одного. Поэтому я собрал те SEO букмарклеты, которые пригодятся PPC специалистам и написал еще несколько своих.
Как установить и использовать букмарклет
Все букмарклеты, представленные в подборке ниже, будут обычными текстовыми ссылками. Установить их можно одним из двух способов:
- Кликните по ссылке левой кнопкой мыши и перетащите на панель закладок в свободное место.
- Скопируйте ссылку и создайте новую закладку через контекстное меню панели закладок — добавить страницу/создать закладку (зависит от браузера). В названии укажите любое вам удобное, а в URL вставьте скопированную ссылку.
Мои авторские букмарклеты
Для разогрева дам вам три простейших букмарклета, а потом будем усложнять. Перед тем, как перетаскивать ссылку к себе в закладки, по ней можно просто кликнуть и проверить как она будет работать (относится ко всем апплетам, кроме парсеров, т.к. их примеры я рассматривал на отдельной странице).
YM & GTM Detector — скажет установлены ли на сайте Яндекс Метрика и Google Tag Manager. Да, их так же можно найти в коде сайта, но ведь лучше потратить секунду на клик, чем минуту на поиск в коде.
300yaGPT — копирует ссылку текущей страницы в буфер обмена и перенаправляет в сервис 300.ya.ru. В нем нужно нажать ctrl+v и отправить бота нейросети Яндекса на подготовку краткого пересказа скопированной страницы. Полезный апплет в тех случаях, когда нужно работать с лонгридами (помогает быстро уловить суть посадочной).
YM Debuger — дописывает в конец ссылки текущей страницы get-параметр, который открывает дебагер Яндекс Метрики. Букмарклет понимает, есть ли в ссылке другие параметры и будет дописывать свой корректно. Если вы никогда не пользовались дебагером Метрики, то я настоятельно рекомендую попробовать. Он дает много полезной технической информации и помогает найти ошибки в настройках аналитики (в ближайшее время по этой теме будет отдельная статья). Изначально дабагер открывается в свернутом виде в правом нижнем углу страницы:

DataLayer cheker
DL Cheker помогает в один клик посмотреть содержимое уровня данных. Он соберет все, что туда передавалось с момента запуска страницы в JSON файл и откроет его на соседней вкладке. Таким образом вы сможете легко проанализировать настроена ли на сайте ecommerce аналитика или GTM и что конкретно передается. Тоже самое можно сделать и через консоль браузера, но это займет у вас на много больше времени и требует технических знаний, а с помощью букмарклета это можно сделать в один клик
Примерно так у вас будет выглядеть открывшаяся после клика страница:

Парсер страницы по селектору
P.S. Этот и следующий парсеры достаточно сложны к пониманию, если у вас нет базовых навыков в HTML и XPath. Поэтому, если считаете, что вам это не очень нужно, смело пропускайте и читайте дальше про seo апплеты. Там будет еще много полезных букмарклетов, не требующих от вас специфических знаний.
Selector Parser by Zurov — запрашивает css селектор того, что нужно спарсить. На выходе вы получаете txt файл со всеми подходящими по селектору тегами. При этом парсер ищет не только содержимое тегов (контент), но и значение атрибутов src и href. Наиболее частые сценарии применения в моей практике:
- парсинг меню сайта с названиями и ссылками на категории товаров для csv фида товарных листингов Яндекс Директа;
- парсинг названий товаров, цен и ссылок на них со страницы категории (опять же для фидов);
- сбор урлов всех картинок;
- сбор контента определенных тегов (к примеру, когда все УТП на лэндинге расположены в подзаголовках с определенным классом — h6.advantages).
Здесь важно пояснить, что вам не нужны полные селекторы, которые обычно копируются из консоли при исследовании элемента. Нужны широкие селекторы, которые подходят сразу для нескольких элементов (ведь парсить один элемент не имеет смысла). К примеру, селектор:
- a — поможет спарсить все ссылки со страницы с их url (href) и контентом;
- a.footer — спарсит все ссылки с классом footer (у меня на сайте таких нет, вам выдаст пустой файл — это просто пример);
- img — спарсит все ссылки на картинки;
- [class*=»wp-image»] — спарсит только картинки с текущей страницы у которых класс содержит wp-image;
- ul[id*=»menu-glavn»]>li.item>a — спарсит главное меню сайта (все ссылки <a>…</a>, вложенные в элементы списка <li>…</li> с классом item, являющиеся потомками списка <ul>…</ul>, у которых атрибут id содержит menu-glavn) ;
- ul[class=»sub-menu»]>li.item>a — спарсит подменю верхнего меню (логика та же, но мы целимся в список с классом sub-menu с точным равенством, а не «содернжит»);
- li.item>a — спарсит оба вышеописанных меню и еще боковое, т.к. у них у всех есть элементы <li>…</li> с классом item с вложенными в них ссылками <a>…</a> и, при этом, мы не ограничивали парсинг только одним списком;
- h1, h2 … h6 — спарсит заголовки h1 (первого) — h6 (шестого) уровня. Вводить только один из уровней.
Если все равно не очень понятно, давайте для примера разберем мою тестовую страницу со списком услуг по контекстной рекламе:
1. Кликнем на ней по названию первой товарной позиции правой кнопкой мыши и выберем пункт «Исследовать элемент»/»Посмотреть код» (или похожее название, зависит от браузера);
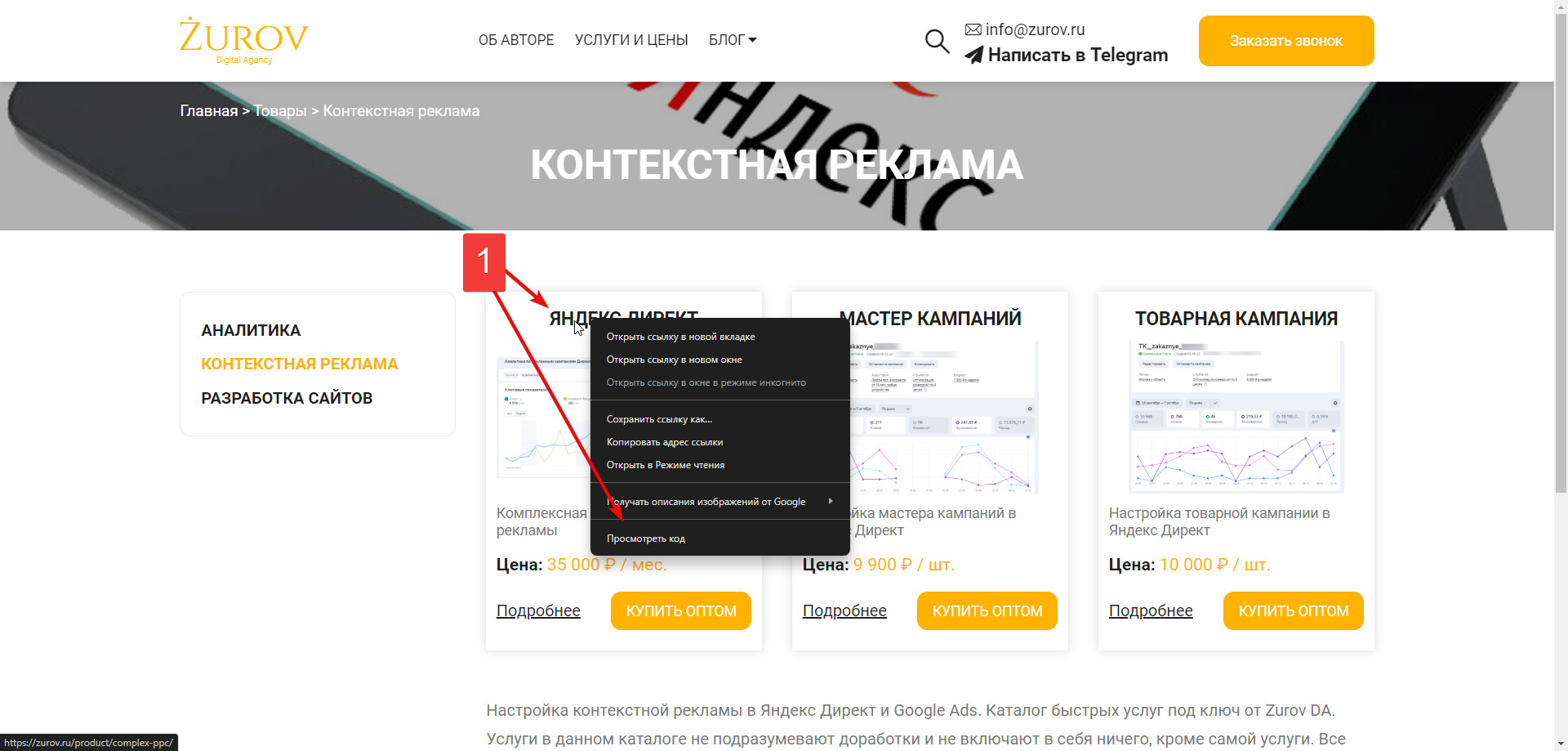
2. В открывшейся «Панели разработчика» будет выделен элемент кода, который мы исследуем. По идее это должен быть тег <a>…</a> со ссылкой на товар и текстовым описанием внутри.
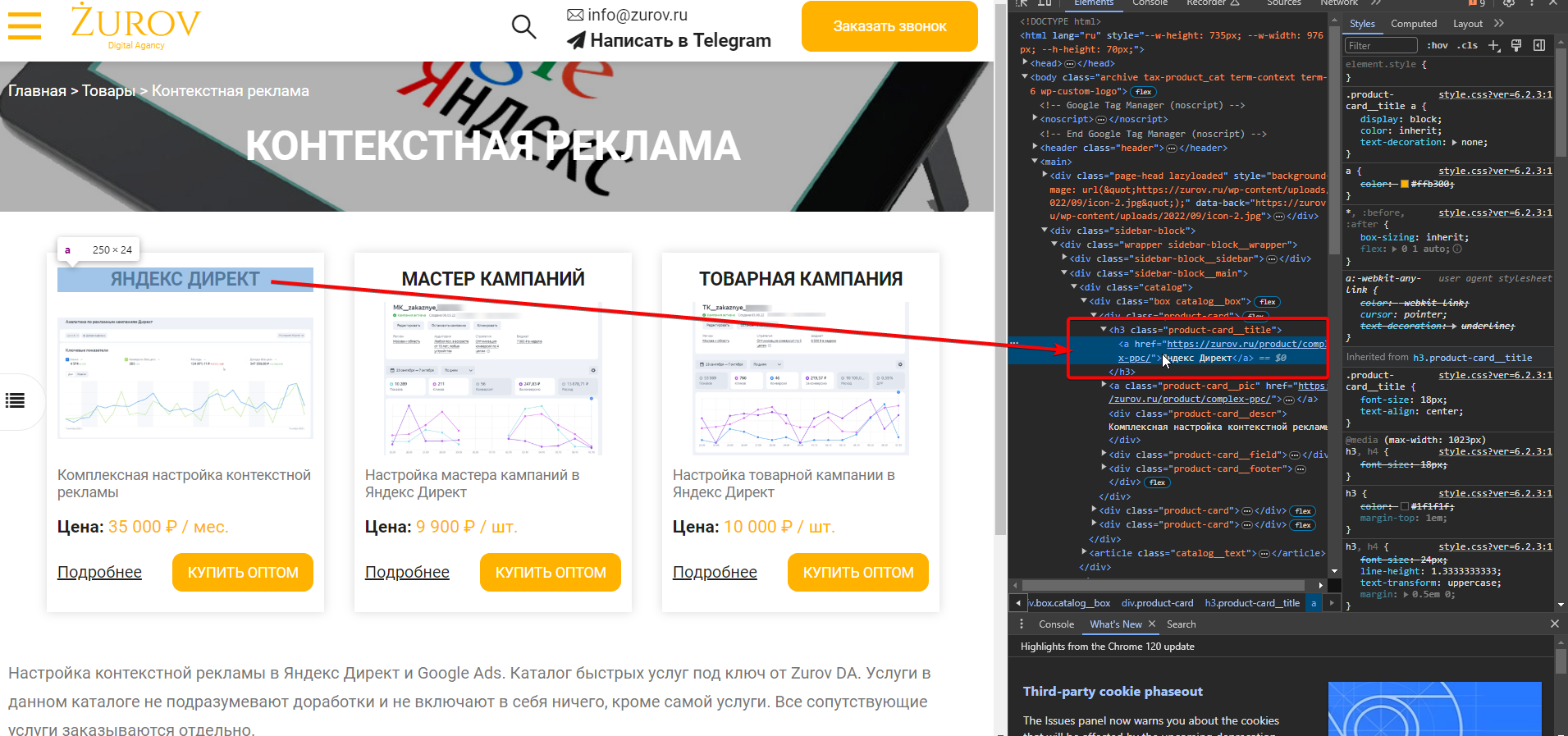
3. Но, т.к. у тега <a>…</a> нет никаких атрибутов, за которые мы бы могли зацепиться (ни class, ни id и т.п.), то нам придется подняться на уровень выше и посмотреть за что мы можем зацепиться там.
Я выписал код в удобочитаемом формате и убрал из него то, что для нас не имеет значения, заменив на «//…»
<div class="product-card"> <h3 class="product-card__title"> <a href="https://zurov.ru/product/complex-ppc/">Яндекс Директ</a> </h3> <a class="product-card__pic" href="https://zurov.ru/product/complex-ppc/"> <img src="https://zurov.ru/wp-content/uploads/2018/01/TGO-SM-DO-450x213.png" class="attachment-medium wp-post-image" data-src="https://zurov.ru/wp-content/uploads/2018/01/TGO-SM-DO-450x213.png" /> //... </a> <div class="product-card__descr">Комплексная настройка контекстной рекламы</div> <div class="product-card__field"> <div class="product-card__key">Цена:</div> <div class="product-card__value product-card__price">35 000 ₽ / мес.</div> </div> //... </div>
Если мы посмотрим на строки 2-4, то увидим, что нужная нам ссылка обернута в тег h3 с классом product-card__title, но, если мы нацелимся на селектор h3.product-card__title, то парсер на выходе отдаст нам все теги <a>…</a> целиком, а не их контент и ссылку из атрибута href, ведь в h3 вложены именно теги, а не обычный текст. Поэтому мы должны задать такой селектор — h3.product-card__title > a (найти все ссылки, вложенные в заголовки h3 с классом product-card__title.
Еще парочка примеров селекторов из кода выше:
- img.wp-post-image — спарсит все ссылки на изображения, содержащие класс wp-post-image;
- div.product-card__price — спарсит контент тегов div с указанным после точки классом;
- div[class=»product-card__field»] div — спарсит контент всех вложенных <div> в тег <div class=»product-card__field «>…</div>. При этом уровень вложенности не имеет значения, т.к. мы записали второй div через пробел, а не через > (если бы записали так div[class=»product-card__field»]>div это бы означало только один уровень вложенности или по умному «только прямые потомки»).
Когда вместо класса нужно искать по любому другому атрибуту, например по id, тогда в скобках просто замените class на id. Так же id, как и class поддерживает упрощенную запись, примерно так — #moy-id div (спарсит все элементы div, вложенные в любые элементы с id=»moy-id»). Записывать id нужно начиная именно с решетки, а не с точки.
P.S. Основы селекторов я вам дал, но, если вам хочется изучить их углубленно, могу рекомендовать статью Якова Осипенкова. Она написана именно для маркетологов, поэтому сидеть со словарем не придется.
XPath парсер страниц
XPath parser by Zurov — этот парсер делает то же, что и первый, но использует для парсинга не css селекторы, а язык запросов XML. Его главным отличием является то, что он может извлечь не только контент тега или атрибуты src/href, но и любой другой атрибут.
Вернемся к нашему примеру выше и извлечем с моей тестовой страницы у всех картинок атрибут data-src. Для этого после запуска парсера впишем туда такой XPath — //a[@class=’product-card__pic’]/img/@data-src. Поменяв в нем @data-scr на @width мы можем извлечь ширину картинки и т.п. В целом это очень полезный функционал, т.к. в таких атрибутах может зашиваться цена товара до скидки и другие характеристики.
Если не использовать в XPath хвост в виде /@atribut, тогда он спарсит контент тега, а не атрибут. К примеру для заголовков товаров будет такой путь — //h3[@class=’product-card__title’]/a.
Если хотите изучить XPath углублено, предлагаю мою статью по созданию фидов для контекстной рекламы без разработчика. Там этот функционал описан с примерами и плюсом вы научитесь собирать фиды для любого типа бизнеса.
Букмарклеты сторонних разработчиков
Как писал выше, я оставлю тут только те seo букмарклеты, которые посчитал полезными для PPC специалиста и расскажу где я их использую.
Счётчик символов выделенного текста — функционал понятен из названия. Мне помогает прикинуть, влезет ли интересующий меня на посадочной странице текст в какой-либо элемент объявления (ведь на все есть ограничение по символам).
Подсветка заголовков H1-H6 — выделяет цветом и подписывает уровни заголовков. Помогает быстро без анализа кода получить структуру контента и подчеркнуть для себя самое важное на странице. Также ускоряет отбор нужных элементов для парсеров.
Анализ контента (текста) страницы — выдает сводку по ТОП10 встречаемых слов (в т.ч. с лематизацией), ТОП10 биграмм и еще несколько показателей по ТОПу слов. Помогает быстро найти идеи для ключевых слов в контекстной рекламе.
Проверка микроразметки — отправляет страницу на проверку микроразметки Schema.org. Если на сайте есть такая разметка для товаров или листингов, то рекламные кампании, работающие на принципе парсинга сайта, запустятся и будут нормально функционировать с большей вероятностью.
Поиск выделенного текста — ищет выделенный на странице текст на всех страницах сайта, попавших в индекс Google. Помогает найти альтернативные посадочные для рекламы по ключу. Нужен, т.к. не всегда на сайте есть встроенный поиск, а если и есть, то он не всегда ищет по всем страницам. К примеру, часто на ecommerce сайтах есть поиск только по товарам, но на этом же сайте есть и блог, содержащий интересующий вас ключ, куда можно загонять людей на начальных стадиях воронки.
Анализ метатегов — выводит Title, Description с их длиной, а так же сводные данные по контенту. Title и Description обычно отображают суть документа, ведь они предназначены для показа в seo выдачи и по ним человек должен принять решение — переходить на сайт или нет. Поэтому можно за пару секунд понять о чем речь на странице. К тому же эти теги можно парсить как заголовки и тексты объявлений.
WebArchive — проверка страницы в веб-архивах. Помогает при аудитах, например, когда к вам обращаются с целью увеличения продаж по резко просевшим позициям на сайте. В таком случае можно открыть архивную страницу услуги/товара и посмотреть не менялась ли там цена или иные условия. Так же помогает проверять клиентов на предмет удаления/замены юридических данных на сайте (поверьте, часто это делается не просто так и с такими клиентами тяжело работать).