В статье разберем как создать csv фид для любого бизнеса, будь то фид товаров, категорий товаров, врачей, билетов, гостиниц и любых услуг. Все, что нам для этого потребуется — это Google таблицы, несколько формул и базовое понимание языка XPath (его я вам дам). В идеале еще иметь минимальные знания в html, но можно обойтись и без них. Более того, вам даже не потребуется доступ к коду сайта и вы не рискуете ничего сломать. Мы будем применять в работе принципы парсинга данных с web-страниц, ни каких заполнений руками. При входе в табличку все данные будут обновляться автоматически.
Для примера создадим CSV фид категорий товаров для товарной кампании Яндекс Директа, а так же универсальный фид Яндекса и специальный фид Google рекламы для любых товаров и услуг (полный список всех возможных фидов и их полей я приведу в конце статьи). На их основе вы сможете простым переименованием столбцов создать любой поддерживаемый формат csv-фида для Яндекс Директа, Google Ads и VK Рекламы.
План действий следующий:
- разберемся, что такое XPath и зачем он нам нужен;
- на примере моего тестового каталога товаров создадим фид товарных листингов Яндекс Директа и подключим его к рабочей ТК;
- создадим фид для смарт-баннеров и динамических объявлений Директа;
- разберемся, как открыть доступ к фиду по ссылке;
- соберем «Специальный фид Google Рекламы» и «Фид Google Shopping«;
- посмотрим, какие еще типы фидов можно создать и какие можно использовать в VK Рекламе, Google Ads и Яндекс Директе;
- получим списки URL’s для парсинга.
Что такое XPath и зачем он нам нужен?
XPath (XML Path Language) — это язык запросов к элементам XML-документа. Разработан для организации доступа к частям документа XML в файлах трансформации XSLT и является стандартом консорциума W3C. XPath призван реализовать навигацию по DOM в XML.
Википедии
Если упростить, то с помощью XPath мы сможем нацелить наш парсер на тот элемент web-страницы, данные которого мы хотим получить. Те, кто давно работает с GTM, могут сравнить его с css селектором. В качестве программы парсера мы будем использовать обычную Google Таблицу и её встроенную функцию IMPORTXML. Последняя позволяет импортировать данные из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML. Нас интересует импорт из HTML документов.
Синтаксис функции следующий:
IMPORTXML(URL; XPath_запрос)
- URL – адрес страницы, с которой мы планируем импортировать данные (протокол http:// или https:// обязателен). URl должен быть закавычен или его нужно разместить в отдельной ячейке, а в формуле сослаться на эту ячейку;
- XPath_запрос – запрос на языке XPath для поиска данных на странице. Так же должен быть закавычен.
Пример (запись внутри ячейки Google Таблицы):
=importxml(https://zurov.ru/;"//a/@href") - Неправильный вариант, т.к. URL не в кавычках
=importxml("https://zurov.ru/";"//a/@href") - правильный вариант
=importxml(B1;"//a/@href") - правильный вариант, если URL находится в ячейке B1
=importxml(B1; //a/@href) - неправильный вариант, т.к. XPath не в кавычках
Таким образом мы можем нацелиться на каждый интересующий нас тег или атрибут страницы (товара, услуги или любой иной сущности) и в таблицу подгрузится значение этого элемента. Когда речь идет об одной странице, то смысла в этом мало, но когда мы работаем с десятками или сотнями однотипных страниц, нам будет достаточно только подставить список URL’s и протянуть формулу с парсером в соседней ячейке, а робот уже сам спарсит все нужные нам данные. Останется только правильно назвать столбцы и импортировать лист в CSV — фид готов.
Понимаю, что пока что это все не очень очевидно, поэтому, прежде чем дальше разбирать синтаксис языка XPath, предлагаю сначала самостоятельно создать фид категорий товаров, а потом уже станет проще.
Создаем фид категорий товаров Яндекс Директа своими руками
Создавать фид будем на примере моего тестового каталога продукции. Пришлось специально создать его под эту статью, чтобы не выпрашивать разрешение у клиентов на испытание на их сайтах, поэтому, с целью обезопасить себя от различного рода неприятностей, сообщаю: «хоть там и актуальные цены, они не являются публичной офертой.»
Сделаем фид для трёх категорий товаров/услуг. Их ссылки:
- https://zurov.ru/product_cat/analytics/
- https://zurov.ru/product_cat/context/
- https://zurov.ru/product_cat/web-dev/
P.S. Сейчас я не рассматриваю, где взять список всех URL-ов для парсинга, которых у вас явно не 3. Пока мы просто тренируемся на моем сайте для того, чтобы вы поняли как это работает. К концу статьи у вас будут все необходимые подходы.
Теперь по шагам
- Откройте Google Sheets и создайте шапку таблицы:
| URL | Title | Description | Offer Minimal Price | Currency | Image URL 1 |
- Вставьте в столбец A (с заголовком URL) три ссылки на категории товаров, которые я указал выше, а в столбец B такую формулу:
=char(34)&importxml(A2;"//title")&char(34)
Важное примечание! Копируйте формулы только из специальных полей для кода и формул (таких, как над этим текстом), т.к. кавычки в обычном тексте не правильно интерпретируются Google Таблицами и такие формулы работать не будут.
Получится так:
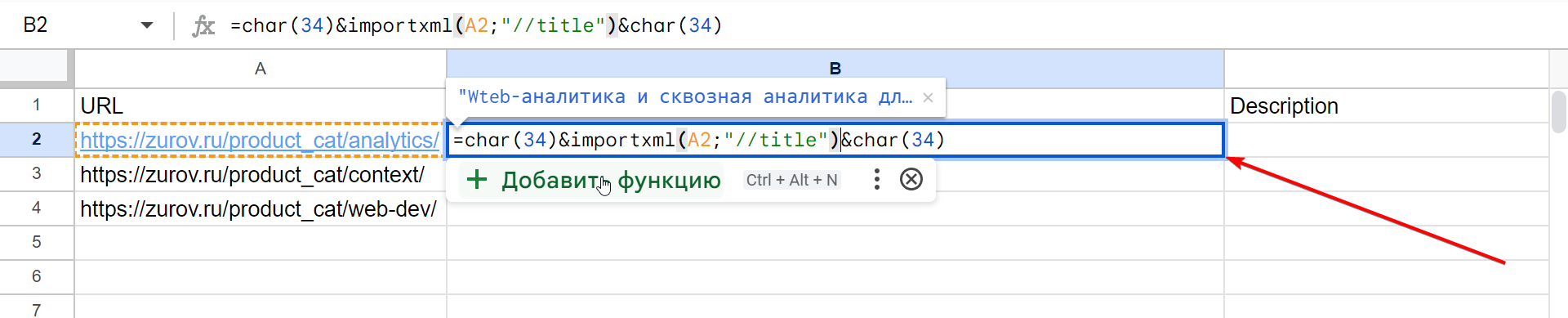
Давайте сразу разберем формулу:
- char(34) — это обозначение кавычки в тех случаях, когда её нужно явно указать текстом, а не как часть формулы. Т.к. к фиду категорий товаров Яндекса есть рекомендация к экранизации текстовых блоков кавычками, мы её выполняем и оборачиваем заголовок (Title) и описание (Description) ими;
- importxml(A2;“//title“) — наша формула, внутри которой мы сначала ссылаемся на ячейку A2, где указана ссылка на страницу парсинга, а затем указываем путь к элементу (XPath), где хранится наш контент — “//title“.
- & — оператор сцепки, хорошо знакомый всем, кто собирает рекламные кампании в excel. В нашем случае мы сцепляем кавычки «char(34)» и спаршенный контент «importxml(A2;»//title»)».
Сразу объясню, что означает «//title» в XPaht — это HTML тег <title> внутри кода спаршенной страницы или просто seo заголовок Title (пункт 1 на скриншоте):

Т.е. конструкция “//title“ обозначает — взять содержимое первого попавшегося на странице тега <title>…</title>.
- Протягиваем за правый край ячейки B2 вниз и получаем спаршенные теги <title> для всех трех категорий.

- В ячейку C2 пишем такую формулу и протягиваем вниз:
=char(34)&importxml(A2;"//meta[@name='description']/@content")&char(34)
Здесь уже XPath сложнее. Давайте разбираться, что к чему. У нас есть сам путь — //meta[@name=’description’]/@content. Этим путём мы парсим seo метатег description. Он располагается в такой конструкции в HTML коде страницы (вверху на рисунке с кодом пункт 2):
<meta name="description" content="Каталог быстрых услуг по настройке систем web-аналитики, сквозной аналитики и GTM. Не является публичной офертой." class="yoast-seo-meta-tag" />
И тут я хочу подсветить одну важную для новичков в HTML мелочь, на которой очень часто спотыкается (особенно digital-маркетологи). Опытные специалисты в HTML могут смело пропустить следующий абзац.
Нужно понимать разницу между html-тегом и html-атрибутом. Визуально тег — это конструкция, которая выглядит так <tag>…</tag> или так <tag />. В нашем случае тегом является <meta /> (кстати, отсюда и название метатег). Тег является самостоятельной единицей html документа. В свою очередь атрибут — это вложенный в тег элемент. В нашем случае атрибутами тега <meta /> являются name, content, и class. У каждого атрибута так же могут быть значения.
Теперь продолжим разбор XPath — //meta[@name=’description’]/@conten. Переводя на человеческий язык это означает — найти первый попавшийся тег <meta>, у которого атрибут «name» равен «description» и спарсить содержимое атрибута content. Исходя из этого давайте разберем синтаксис детально:
- // — означает относительный путь к элементу. Это значит не от начала документа, а от любого подходящего по критериям узла (элемента). В противном случае нам пришлось бы писать путь к нужному элементу так — /html/body/meta[@name=’description’]/@content. Последний вариант является примером абсолютного пути, а одиночный слеш «/», как и в url обозначает вложенность.
- @atribut — находит название атрибута с именем atribut.
- […] — квадратные скобки в XPath называют предикатами. По простому это фильтры. В нашем случае они позволяют найти конкретный тег с нужным значением. К примеру meta[@name=’description’] выбирает только теги meta, у которых есть атрибут «name» со значением «description», а //div/a[@id=’menu’] найдет все теги <a>…</a>, вложенные (потомки) в тег <div>…</div> у которых есть атрибут «id» со значением «menu».
Для закрепления предикатов рассмотрим код:
<div> <a href="https://zurov.ru/1">Отображаемый текст Ссылки 1</a> <a id="menu" href="https://zurov.ru/2">Отображаемый текст Ссылки 2</a> <a id="menu" href="https://zurov.ru/gtm">Отображаемый текст Ссылки 3</a> </div>
- //div/a[@id=’menu’] — выдаст нам «Отображаемый текст Ссылки 2» и «Отображаемый текст Ссылки 3», потому что у «Отображаемый текст Ссылки 1» нет id со значением menu;
- //div/a[2] — выдаст нам «Отображаемый текст Ссылки 2», не из-за того, что в тексте или атрибуте href есть двойка, а потому что мы запросили второй по порядку тег <a> внутри <div>;
- //div/a[contains(@href, ‘gtm’)] ] — выдаст «Отображаемый текст Ссылки 3», т.к. только в ней в атрибуте href содержится «gtm». Внимательно изучите отличие этого примера от первого, где мы разбирали точное равенство, а не «содержит»;
- //div/a[position()<3]/@href — выдаст «https://zurov.ru/1» и «https://zurov.ru/2», т.к. мы выбрали вложенные в <div> теги <a>, у которых позиция меньше трех (1 и 2) и дальше поставили слеш, чтобы спарсить не контент тега <a>, а провалиться глубже и спарсить значение его атрибута href;
- //div/a[contains(text(), ‘ссылки 3’)]/@href — выдаст «https://zurov.ru/gtm», потому что мы выбрали теги <a>, текст (контент) которых содержит «ссылки 3» и запросили значения их атрибутов href;
- //div/a[last()-1] — выдаст «Отображаемый текст Ссылки 2», т.к. был запрошен вложенный (потомок) в div предпоследний тег a (если использовать last() без «-1», тогда выберет последний).
- Перейдем к следующей ячейке D2 и здесь рассмотрим упрощенный подход работы с XPath, но для начала записываем формулу в ячейку и протягиваем её вниз:
=importxml(A2;"/html/body/main/div[2]/div/div[2]/div/div/div[1]/div[2]/div[2]")
Выглядеть будет так:
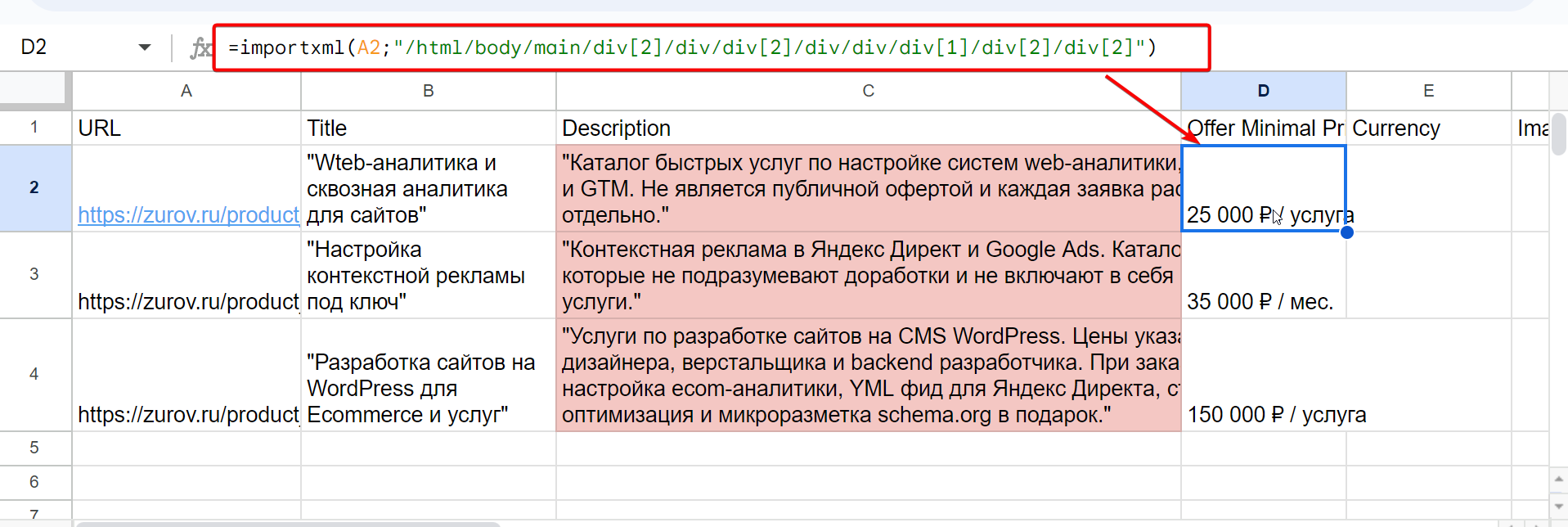
Здесь я уже не оборачивал контент в кавычки, а использовал только чистую формулу, т.к. в блоке с ценой должны быть только числа. Как видите, у меня кроме чисел подтянулись лишние символы. Можно прямо в формуле использовать дополнительные манипуляции, которые позволят достать только числа. Вариантов несколько от простого «Найти и заменить», до усложнения формулы с удалением пробелов и изъятием только чисел. К примеру так:
=REGEXEXTRACT(SUBSTITUTE(importxml(A2;"/html/body/main/div[2]/div/div[2]/div/div/div[1]/div[2]/div[2]"); " "; ""); "\d+")
здесь:
- SUBSTITUTE(формула_парсер; » «; «») — удаляет пробелы;
- REGEXEXTRACT(значение_без_пробелов; «\d+») — оставляет только числа.
Однако это частный случай и у каждого будет своё значение поля с ценой и, соответственно, своя формула в Google таблицах для её преобразования. У кого-то вообще можно будет извлечь сразу цифры без всяких проблем.
Но давайте разбираться, каким образом мы получили такой XPath. Для этого перейдите на страницу одной из категорий товаров, над которыми мы сейчас работаем (https://zurov.ru/product_cat/analytics/) и кликните правой кнопкой мыши по первой цене товара. Далее выберите пункт «Просмотреть код», «Исследовать элемент» или что-то похожее (зависит от браузера):
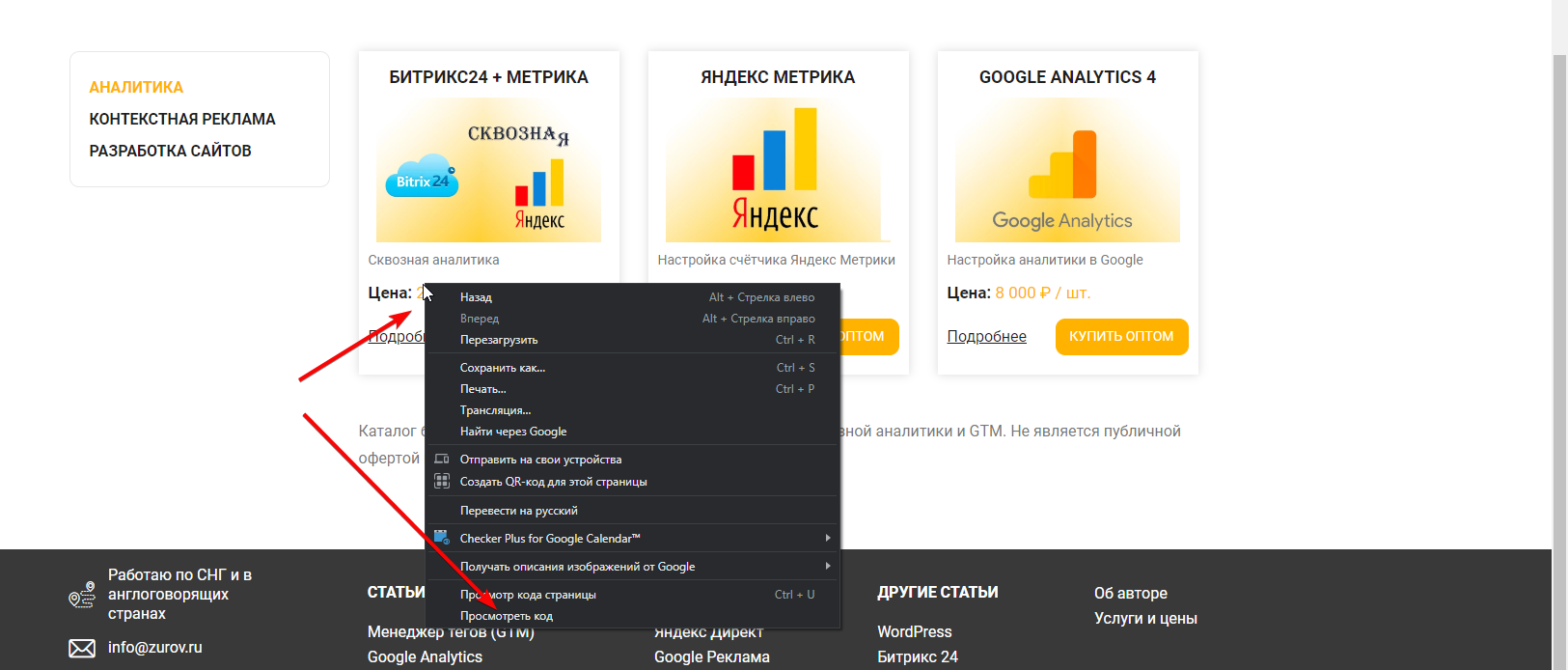
В открывшемся окне будет выделен элемент, который вы сейчас исследуете. Кликните по нему правой кнопкой мыши, выберите пункт «Копировать» (copy) → «Копировать XPath».
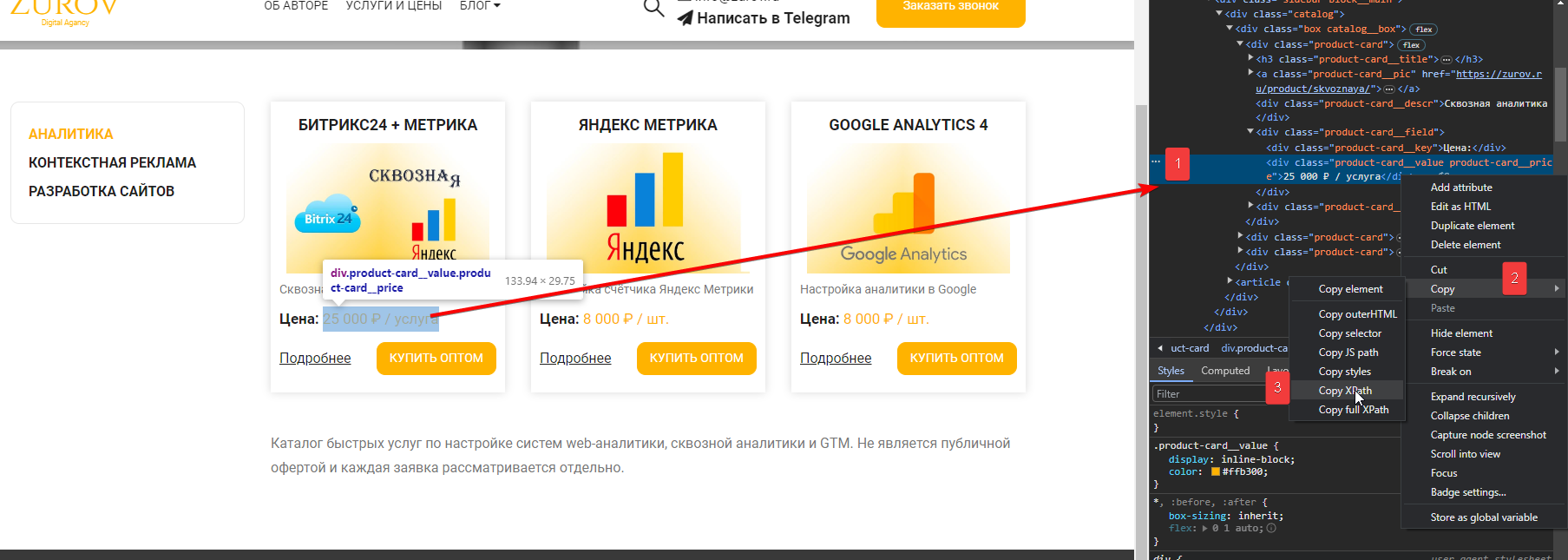
Теперь можно вставить скопированное значение в нашу формулу и растянуть на остальные ячейки.
- В столбец Е (Currency) пропишите код валюты (RUB, BYN, USD, EUR, и т.д.) и растяните на весь столбец.
- Остаётся заполнить поле с картинкой. Я брал её у себя из метатега разметки Open Graph. Она есть на многих сайтах, т.к. она помогает подтягивать картинку к ссылке на страницу, которой вы делитесь в соцсетях. Код этого метатега можно посмотреть выше на картинке с черным фоном и HTML разметкой. Он отмечен цифрой 3. Здесь я вам предлагаю, с учетом полученных знаний, самостоятельно составить XPaht. Я напишу его ниже, чтобы вы потом смогли себя проверить:
=importxml(A2;"//meta[@property='og:image']/@content")
Растягиваем вниз столбца и все готово, а бонусом за терпение я прилагаю ссылку на файл с тем, что мы только что делали. Для того, чтобы вы могли вносить правки, нужно создать копию документа. И дополнительно прикрепляю PDF с требованиями к csv фиду категорий товаров Яндекс Директа, актуальными на момент публикации статьи. Требования готовили технические специалисты Яндекса.
Подключаем фид к товарной кампании в Яндекс Директе
Конкретно фид товарных листингов (категорий) можно подключить только через экспорт данных из Google Таблиц в csv, но я покажу вам еще несколько способов, которые подойдут для динамического обновления фидов в Директе и Google Ads (с VK рекламой все аналогично).
В нашей таблице нажимаем «Файл» → «Скачать» → «формат CSV»
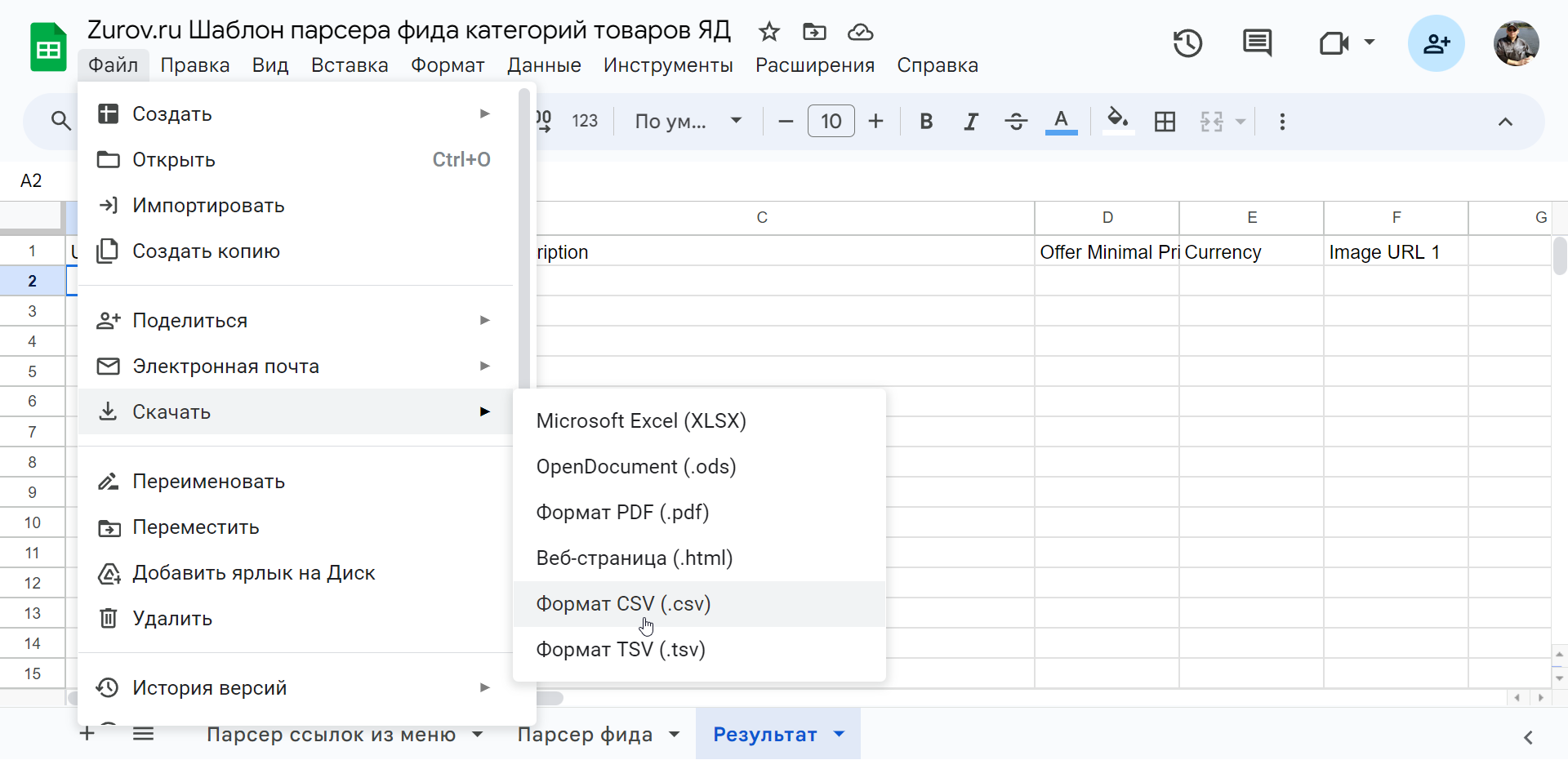
Далее переходим в нужную товарную кампанию Директа и открываем её для редактирования. Напротив пункта «Объявления для страниц каталога» активируем переключатель и выбираем вариант «Файл с компьютера». Загружаем сюда наш файл.
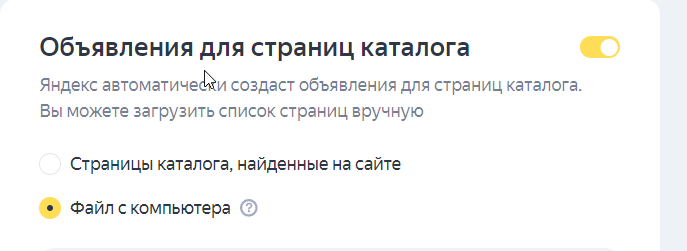
Важно! Файл не пройдет модерацию, если у него будут нарушения требований к фиду, например, по длине заголовков и описаний. Однако это требование относится только к этому типу фида. С другими все несколько проще.
Для решения этой проблемы в Google таблицах можно использовать, например, такую функцию:
=REGEXREPLACE(C3;"(?:\S+\s+){n}\S+$";"")
Функция удаляет n слов с конца строки в ячейке С3. Вместо n нужно подставить нужное количество слов, а вместо С3 нужную ячейку с исходным текстом.
Добавляем фид для всех видов кампаний Яндекс Директа
CSV фиды можно использовать и в библиотеке фидов Яндекс Директа, а оттуда их можно добавлять в Смарт-баннеры, Динамические и Товарные кампании. Для эксперимента предлагаю модернизировать названия столбцов в нашей Google таблице следующим образом:
- переименуем столбцы «Offer Minimal Price» и «Image URL 1» в «Price» и «Image» соответственно;
- добавим в начале столбец ID со значениями 1, 2, 3.
Здесь сразу сделаю пояснение. Когда вы в дальнейшем будете парсить свои фиды, обратите внимание на параметр ID. Если у вас на сайте настроена ecommerce аналитика, то в этот параметр нужно передавать тот же ID, что и в id товара (услуги, билета и т.п.). Это позволит вам настроить динамический ретаргетинг. При этом, если у вас не настроена электронная торговля, тогда мэтчинг будет происходить не по id, а по ссылке и идентификатору можно задать произвольные значения.
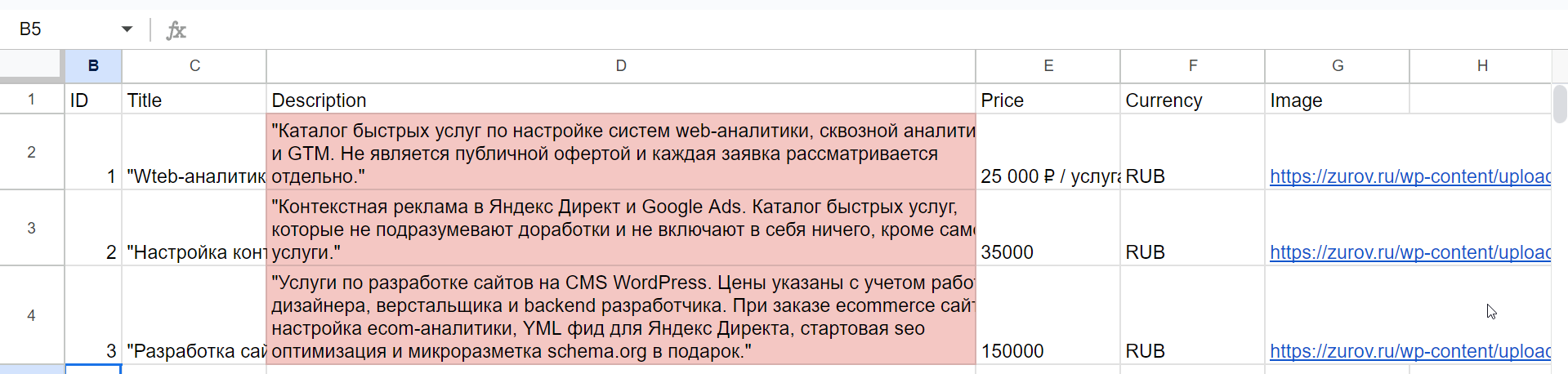
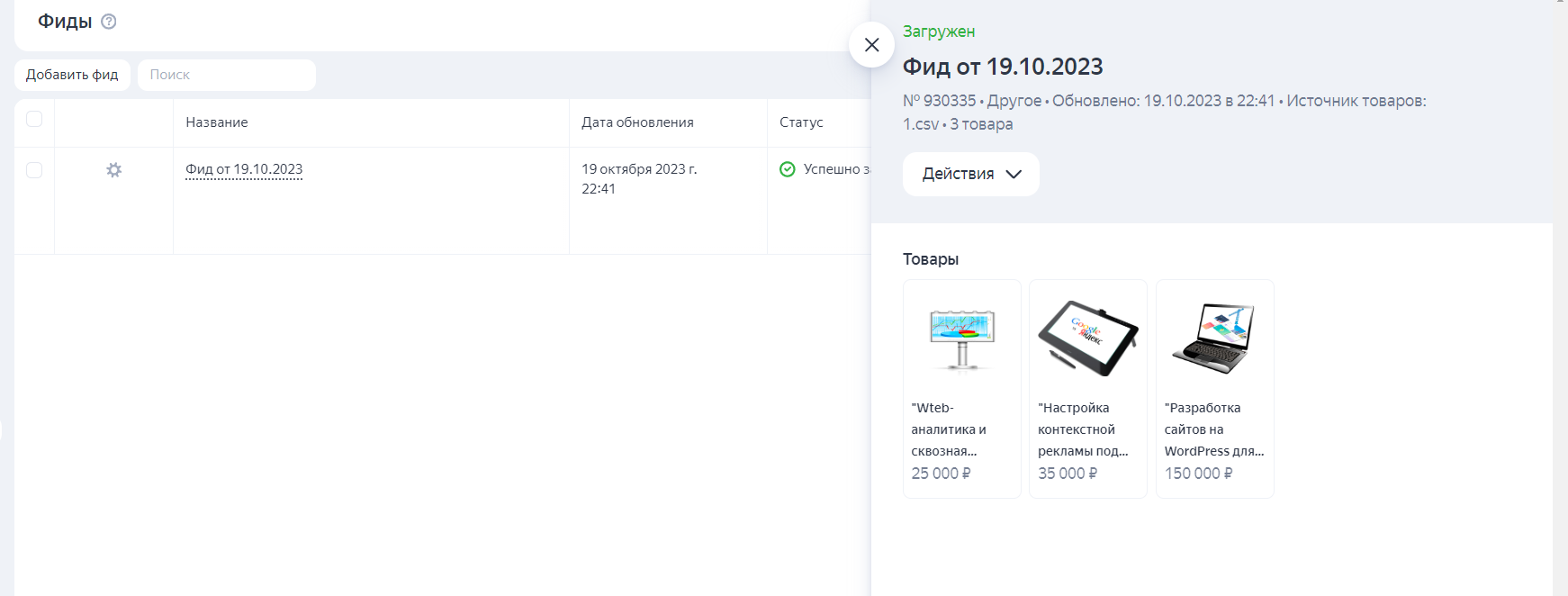
Таким образом мы преобразовали фид листингов Яндекс Директа в универсальный фид. Теперь скачаем его в csv и добавим в рекламный аккаунт ЯД:
- в левом меню выбираем «Библиотека» → «Фиды»;
- на открывшейся странице жмем «Добавить фид» → «Загрузить из файла»;
- выбираем наш файл и тип фида «Другое»;
- жмем «Сохранить».
Фид готов к использованию:
Альтернативный вариант через загрузку файла по ссылке (автообновляемый фид)
Как вы уже поняли, фид не обязательно скачивать. Этот вариант я узнал от моей коллеги эксперта Мариам Оганесян из Adgasm.io (так же именно она подсказал мне про то, что Директ может мэтчить товары из фида с сайтом и аналитикой не только по id, но и по url — писал об этом выше). Последовательность действий следующая:
- в нашей Google таблице открываем меню «Файл» → «Поделиться» → «Опубликовать в Интернете»;
- в открывшемся окне в варианте «ссылка» выбираем нужный лист документа и формат csv;
- жмём «Опубликовать» и «Ок».
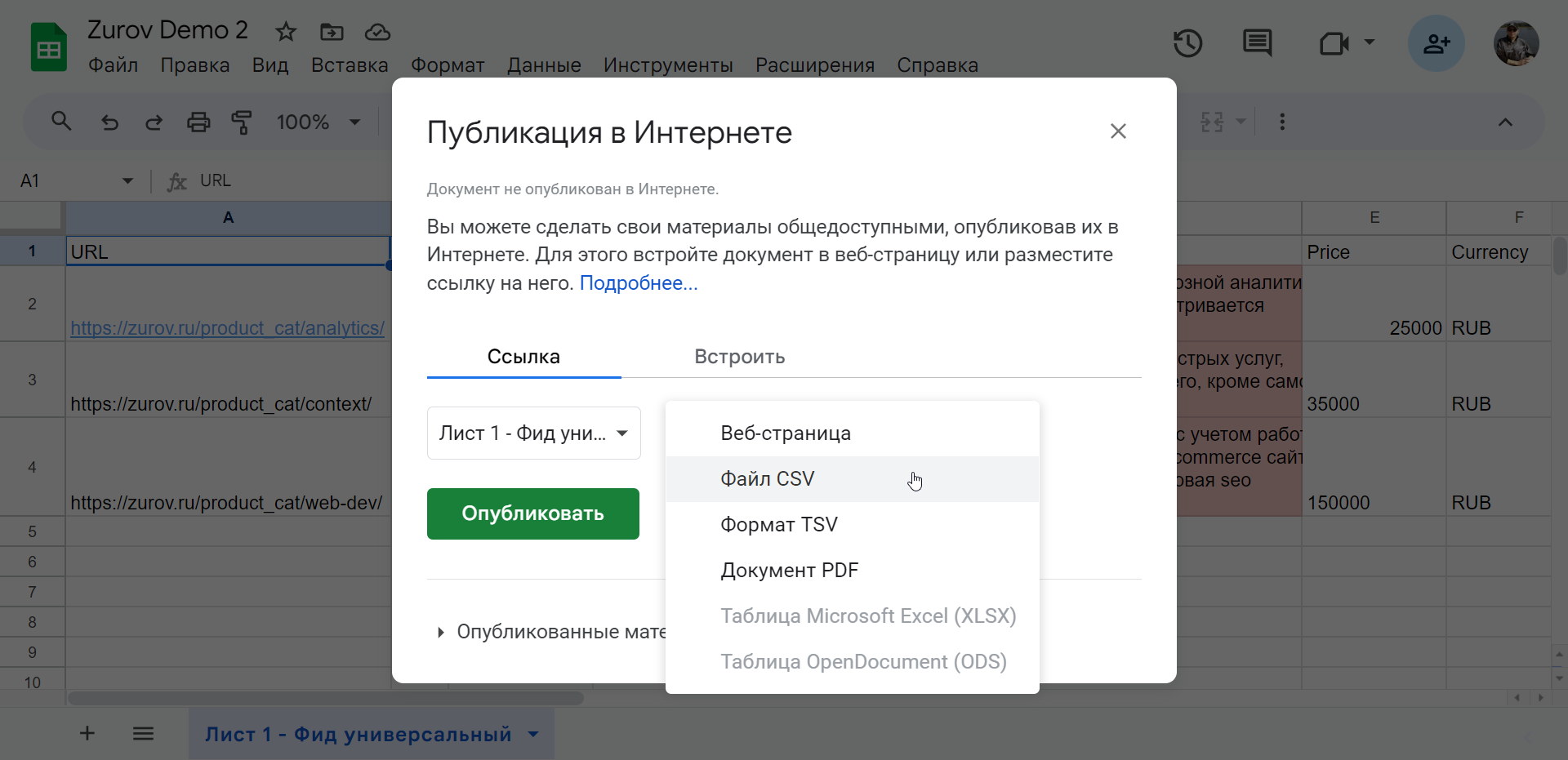
С полученной ссылкой идем в библиотеку фидов, но вместо варианта «Загрузить из файла» выбираем «Загрузить по ссылке». Вставляем ссылку, выбираем тип «другое» и сохраняем фид.
Готово. Теперь у вас есть автообновляемый фид Яндекс Директа, который вы собрали своими руками. И я вам буду очень признателен, если вы удалите его из своего аккаунта, т.к. прочитают эту статью многие, и если каждый добавит фид на мой каталог в Директ, то роботы Яндекса будут DDOS-ить мой сайт. 😉
Специальный фид для Google Рекламы без разработчика
Здесь нам опять придется переименовать столбцы в такие — Final URL, Image URL, Item title, Item description (думаю что во что переименовывать очевидно, поэтому пояснять не стану). А вот с ценой придется поработать, т.к. в этом типе фида она должна быть записана вместе с кодом валюты через пробел в одной ячейке (соответственно столбец Currency нужно удалить). Для этого можно сцепить данные двух ячеек так:
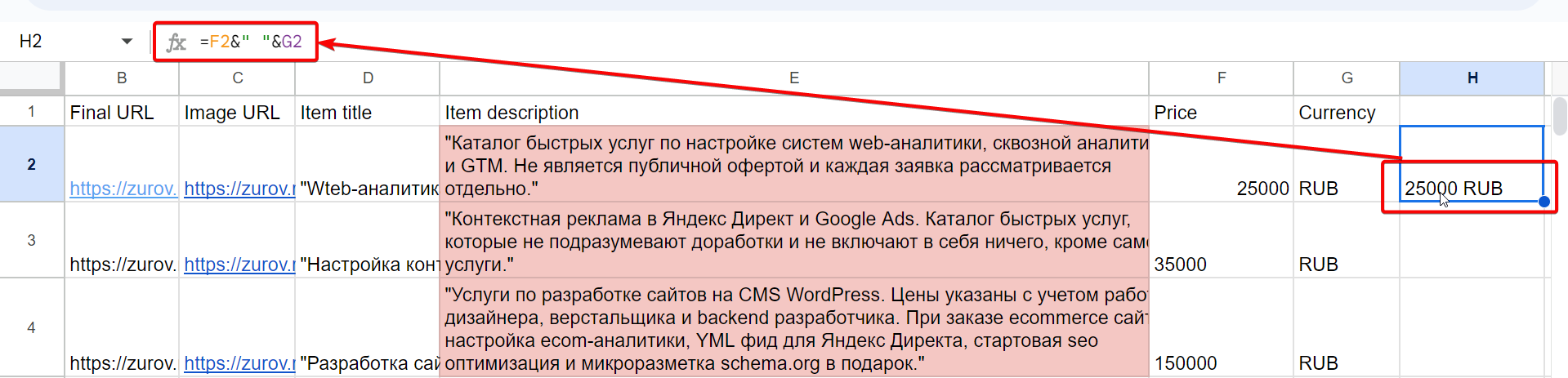
А потом скопировать и вставить в столбец «Price» только значения столбца с ценой и валютой. Или (альтернативный вариант) сразу в формулу парсинга цены в конец дописать:
&" "&"RUB"
Конечный вид фида будет такой:
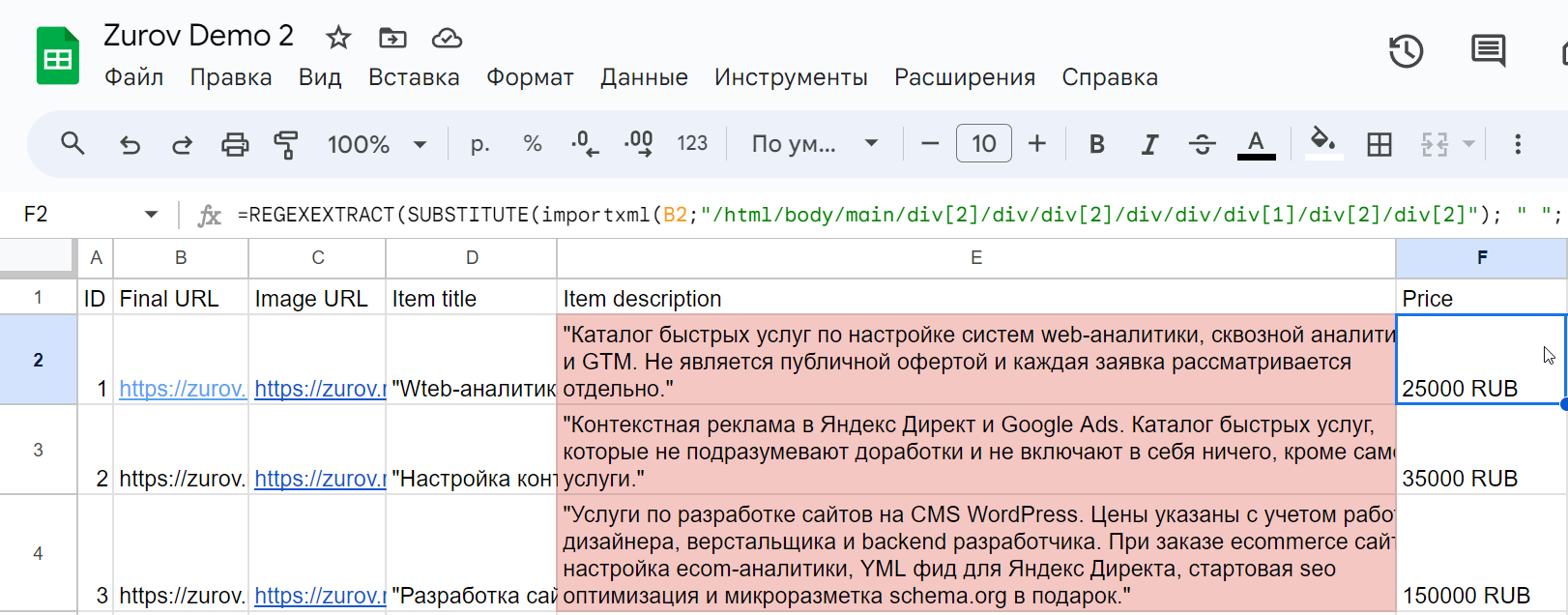
Кстати, этот фид поддерживается не только Google Ads, но и Яндекс Директом, поэтому, если вам нужен универсальный фид для обеих систем, вполне можете использовать его. Пока же добавим фид в Google Рекламу:
- зайдите в «Инструменты» → «Коммерческие данные» → «Фиды данных»;
- выберите «Добавить Фид» → «Фид динамических объявлений» → «Выбранные пользователем»;
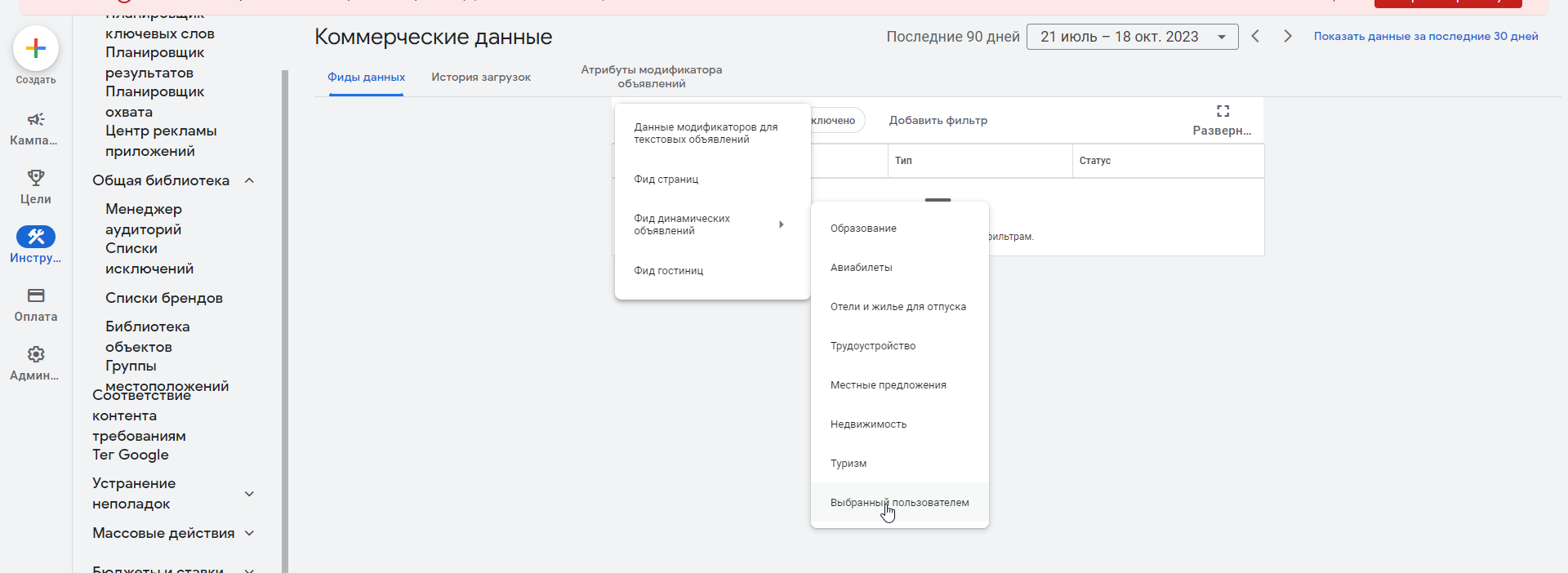
- для загрузки вы можете использовать первые два метода, которые мы применяли к Яндексу (файлом или по ссылке), либо же воспользоваться третьим и просто указать путь к нужной Google Таблице;
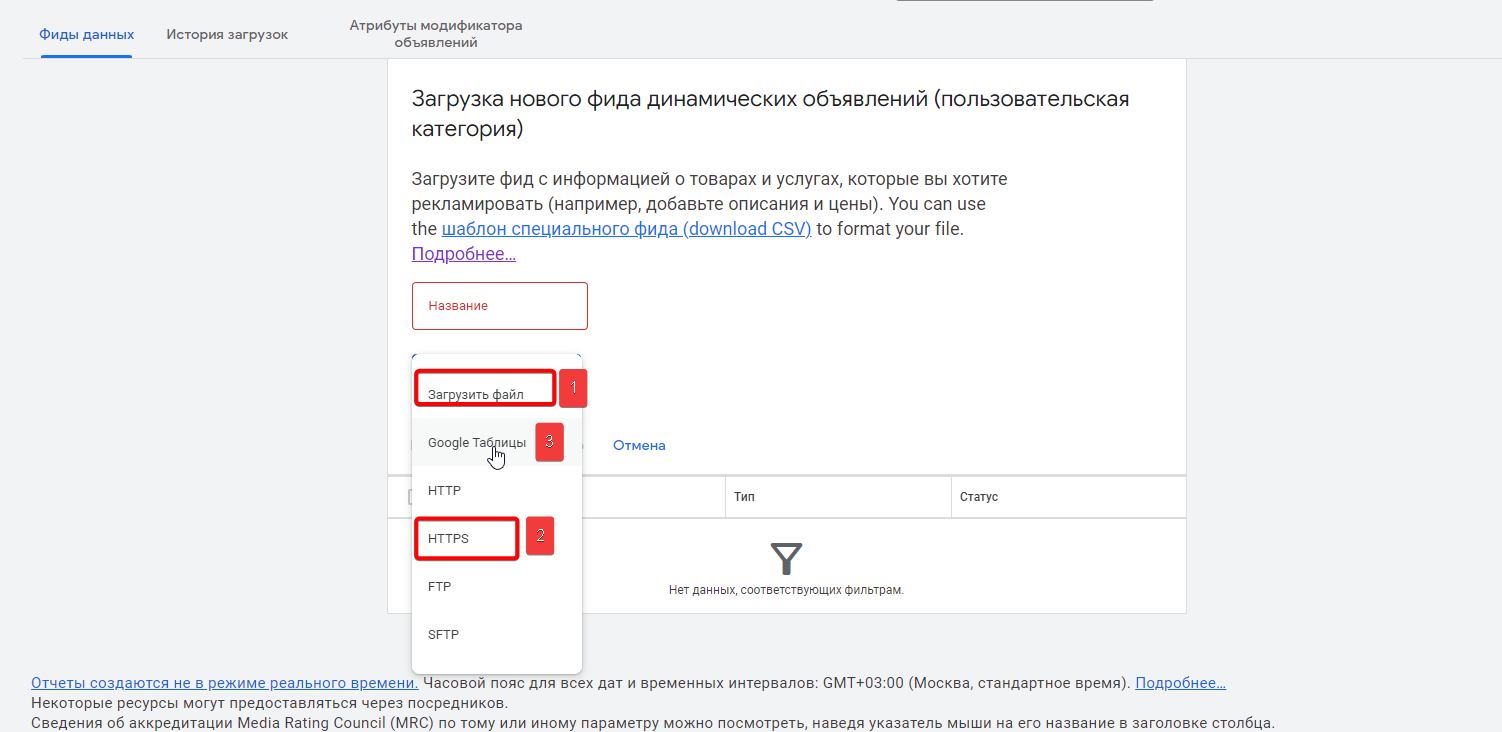
Если вы выбираете вариант загрузки через Google Таблицу, тогда к ней нужно будет предоставить доступ техническому аккаунту Google (вам его дадут во время загрузки фида). Ваш фид должен находиться на первом листе таблице, иначе робот Google Ads его не увидит.
Фид готов, но не забывайте, что для динамического ремаркетинга в Google рекламе нужен не только фид, а, как не странно, еще и настроенный динамический ремаркетинг. Справка Google по его настройке тут. Если будет нужна пошаговая инструкция на эту тему для GTM, пишите комментарии под статьёй, сделаю.
Фид для Google Merchant Center (Google Shoping) без разработчика
Механика парсинга данных для данного типа фида аналогична всем используемым ранее, поэтому не буду повторяться. Дам только рекомендацию по тому, где взять самый полноценный шаблон Google Таблицы для этого типа фида и, к сожалению, это не мой шаблон, т.к. в своем я сделал универсальный вариант, подходящий для Merchant, VK Рекламы и Яндекс Директа (универсальность требует жертв). У GMC есть свой собственный шаблон, который будет автоматически тянуть все изменения из таблице сразу в Merchant Center. В добавок в этом шаблоне расписаны все дополнительные поля и есть ссылки на спецификацию. Поэтому, если делаете фид именно для Google, лучше пользоваться их вариантом, а во всех остальных случаях моим (лист Google Shoping).
Чтобы получить таблицу от Google Merchant:
- Войдите в свой аккаунт Google Merchant Center или создайте новый. Если аккаунт будет на английском, нажмите на шестеренку в правом верхнем углу экрана и в «account settings» выберите русский язык, а затем вернитесь в основную рабочую область.
- В правом меню выберите пункт «Товары», а затем в открывшемся окне ссылку «Создайте фид» (она будет в самом низу).
- Укажите регионы, где будет работать фид и язык.
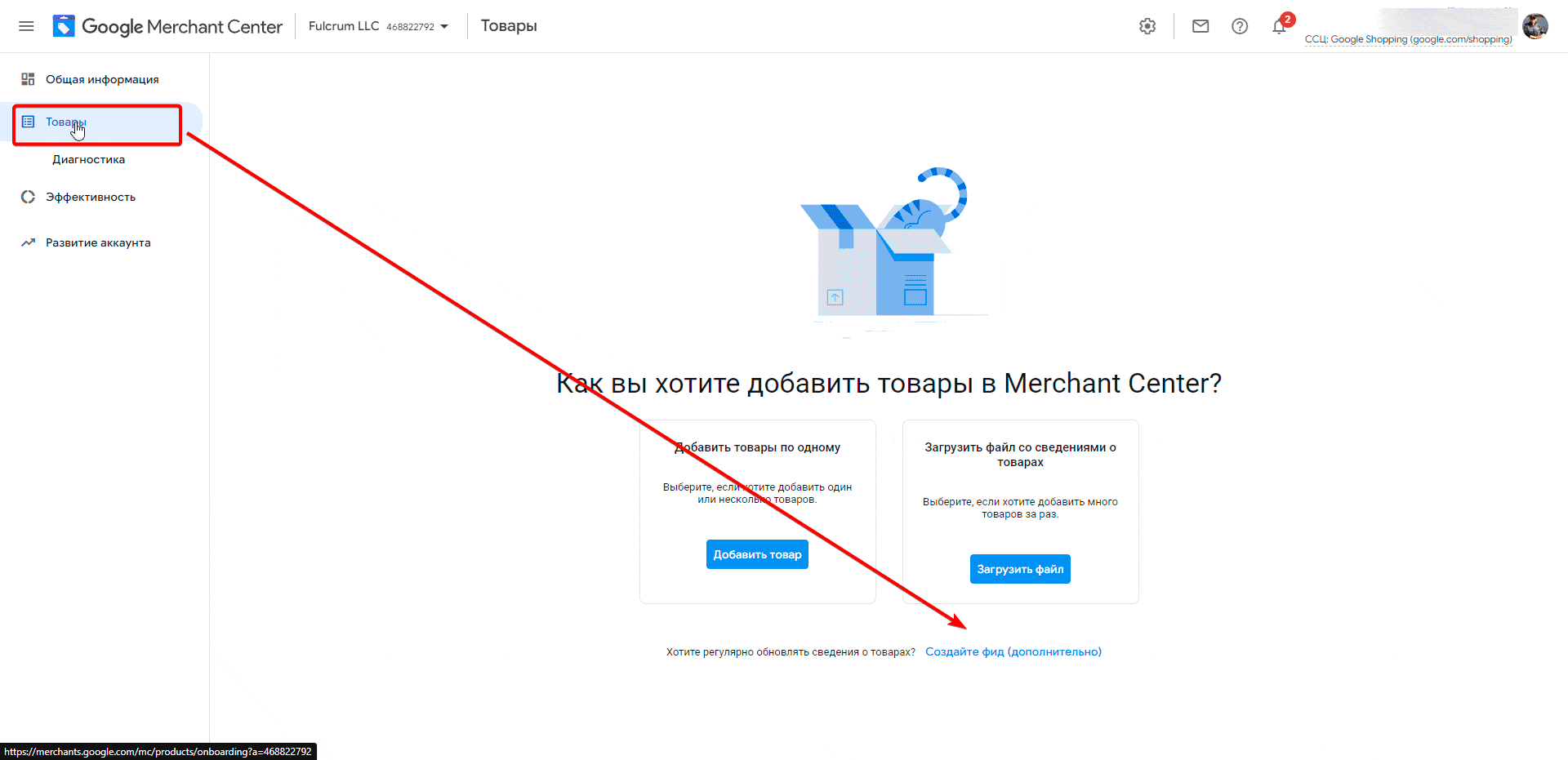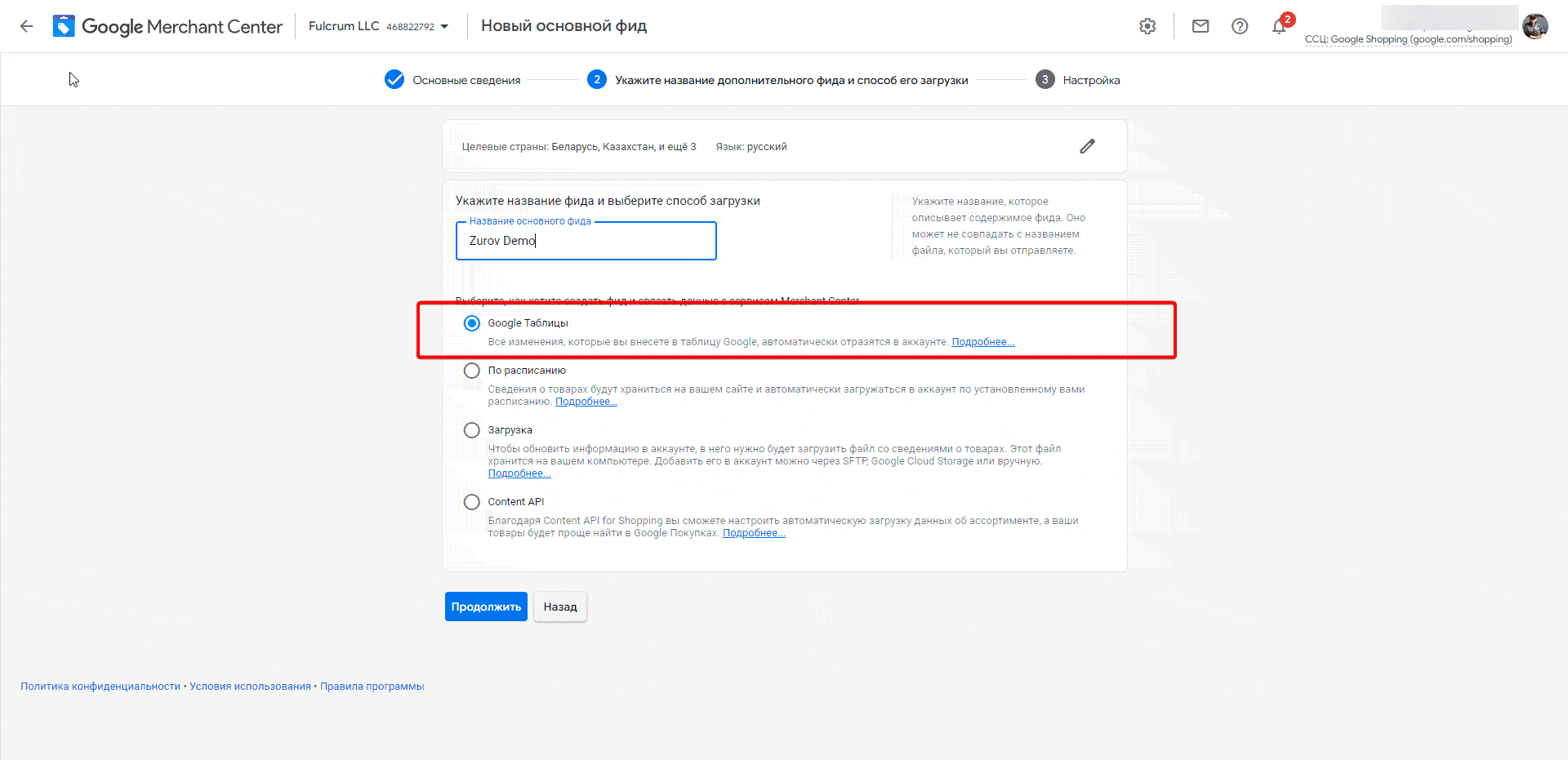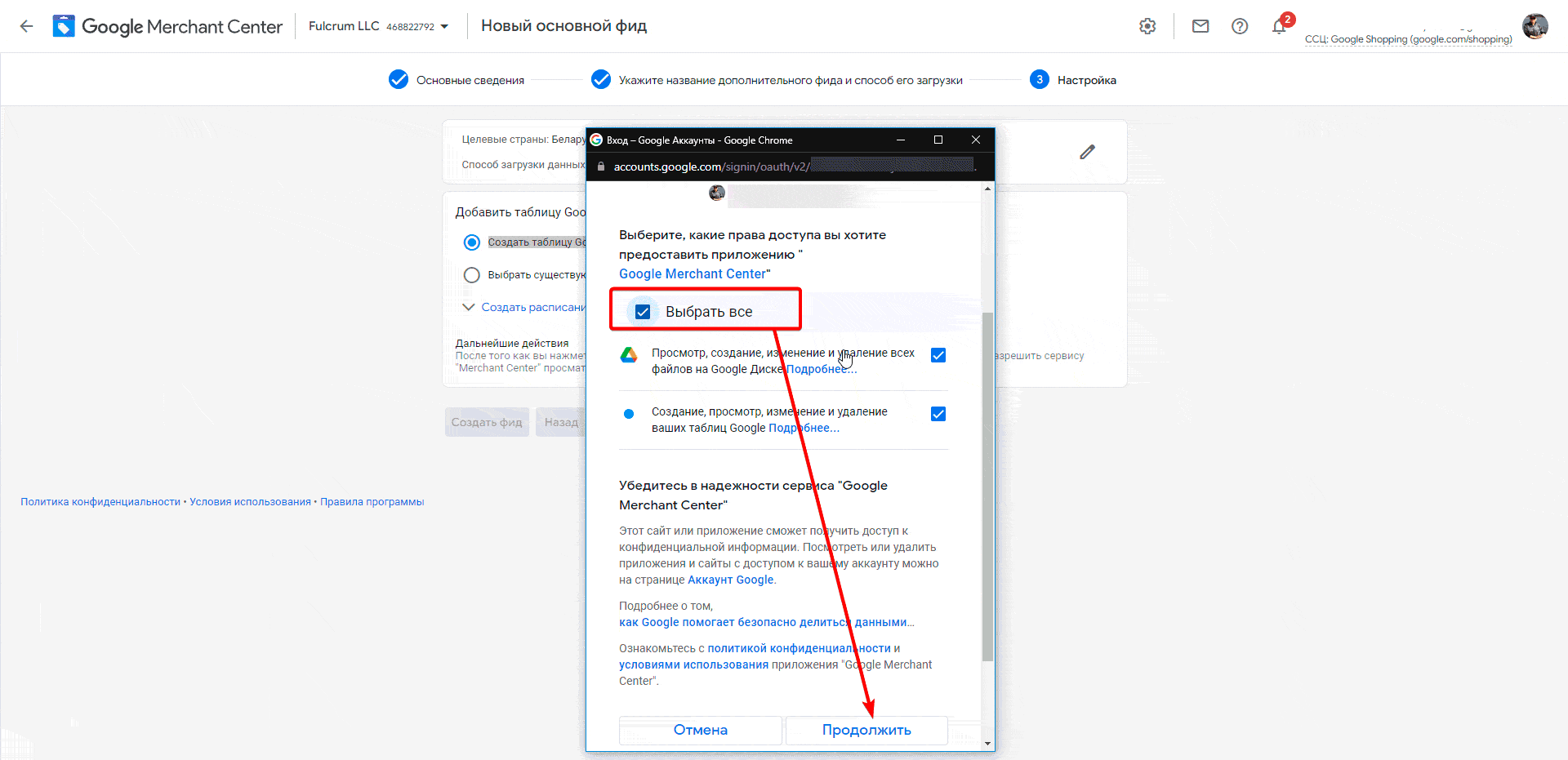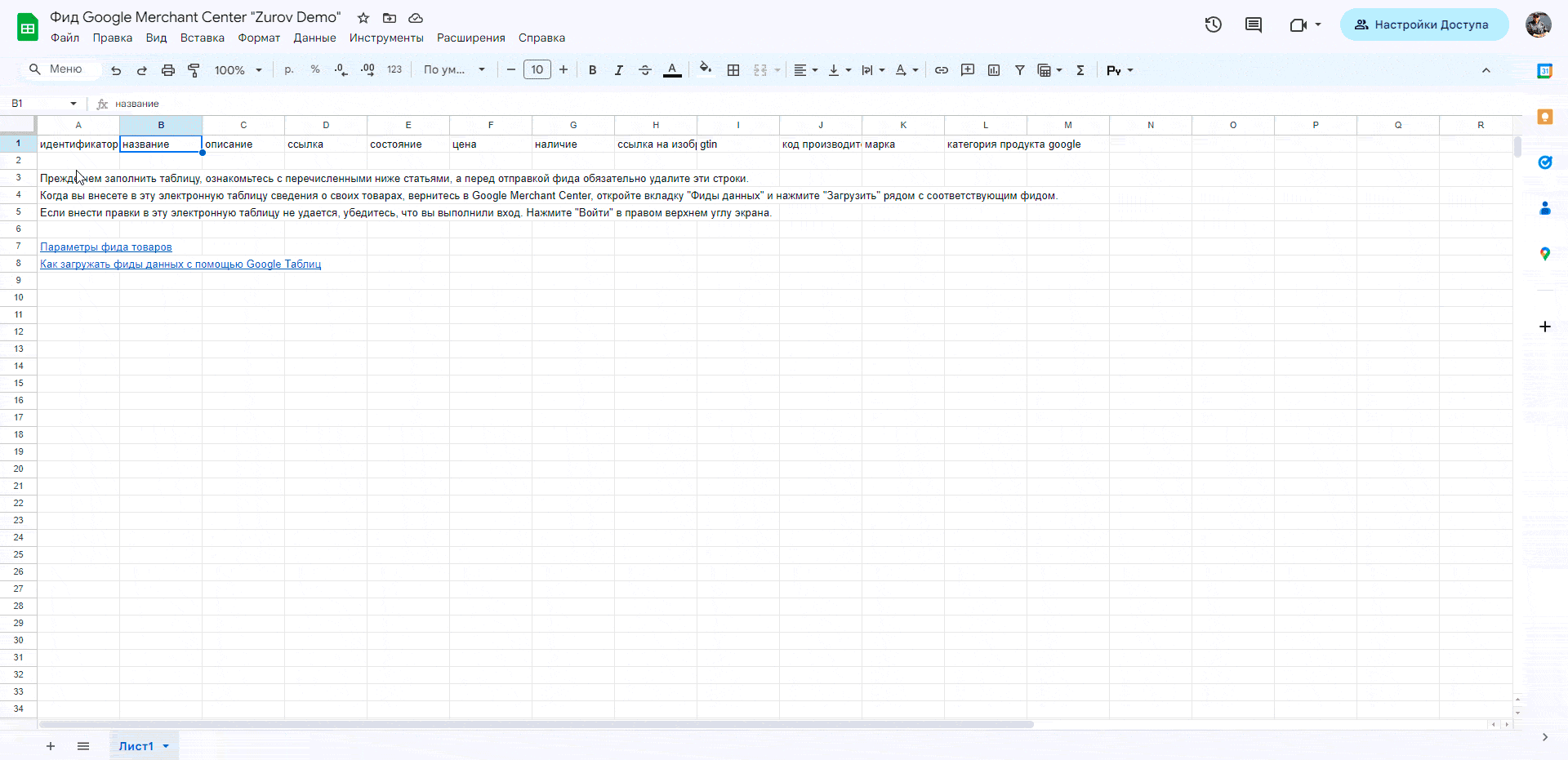
- Дайте фиду название и выберите вариант «Google Таблицы».
- Выберите «Создать таблицу Google по шаблону» и нажмите «Создать фид».
- В появившемся окне выберите тот же аккаунт, через который вы вошли в Merchant и проставьте все галки разрешений. Нажмите «Продолжить».
- Нажмите на «Открыть Google Таблицу». Готово.
Какие фиды поддерживаются
Ниже будет таблица, в которой приведены названия фидов, поддерживающих выгрузку в CSV. К каждому из них дам шапку (названия полей). Приведены не полные, а лишь рекомендуемые наборы данных. Все шаблоны для фидов, описанные здесь, я уже дал вам выше в моем файле шаблонов в предыдущем разделе статьи. В нем цветом отмечены все обязательные/рекомендуемые поля и дана ссылка на документацию.
| Тип фида (csv) | Рекламная система | Тип бизнеса Яндекс | Для чего | Список параметров |
| Фид Google Shopping | Google Ads, Google Merchant, Яндекс Директ, VK Реклама | Розничная торговля, Другой бизнес | Розничная торговля товарами, кроме отелей, автомобилей, недвижимости и авиабилетов | id, title, price, link, image_link, brand, availability, description, condition, product_type, sale_price, gender, age_group |
| Фид «Специальный» Google Рекламы | Google Ads, Яндекс Директ | Другой бизнес | Любые товары и услуги, кроме отелей, автомобилей, недвижимости и авиабилетов | ID, Final URL, Image URL, Item title, Item description, Price, Sale price |
| Универсальный фид | Яндекс Директ | Другой бизнес | Любые товары и услуги, кроме отелей, автомобилей, недвижимости и авиабилетов | ID, URL, Image, Title, Description, Price, Currency, Old Price |
| Фид «Отели и аренда жилья» Google Рекламы | Google Ads, Яндекс Директ, VK | Отели | Бронирование отелей | Property ID, Property name, Final URL, Image URL, Destination name, Description, Price, Sale price, Star rating, Category, Address, Score, Max score, Facilities, Locality, Region, Country, Metro |
| Фид «Авиабилеты» Google Рекламы | Google Ads, Яндекс Директ, VK | Авиабилеты | Продажа авиабилетов | Destination ID, Destination name, Origin ID, Origin name, Final URL, Image URL, Flight price, Flight sale price, Flight description, ID (только для VK) |
| Фид «Путешествия» Google Рекламы | Google Ads, Яндекс Директ | Другой бизнес | Продажа туров, билетов на поезда, паромы, автобусы и т. д. | Destination ID, Destination name, Destination address, Origin ID, Origin name, Final URL, Image URL, Title, Price, Sale Price |
| Фид категорий товаров Яндекс Директа | Яндекс Директ | Розничная торговля | Продажа товаров (загрузка через интерфейс товарной кампании ЯД) | URL, Title, Description, Offer Minimal Price, Currency, Image URL 1, Image URL 2, … , Image URL 5 |
| Фид Google Образование | Google Ads | Курсы, вебинары | Program ID, Location ID, Program name, Final URL, Thumbnail image URL, Image URL, Area of study, Program description, School name, Contextual keywords, Address | |
| Фид Google Вакансии | Google Ads | Вакансии | Job ID, Location ID, Title, Final URL, Image URL, Subtitle, Description, Category, Contextual keywords, Address, Salary | |
| Фид Google Местные предложения | Google Ads | Локальный бизнес | Deal ID, Deal name, Final URL, Image URL, Subtitle, Description, Price, Sale price, Category, Contextual keywords Address | |
| Фид Google Недвижимость | Google Ads | Продажа и аренда недвижимости | Listing ID, Listing name, Final URL, Image URL, City name, Description, Price, Property type, Listing type, Contextual keywords, Address | |
| Фид VK Недвижимость | VK | Продажа и аренда недвижимости | id, title, address, location.country, location.region, location.locality, price, image_link, link, brand, metro.name, sale_price, min_price, max_price, description, num_beds, num_baths, num_rooms, floor, floors_total, property_type, custom_label, listing_type, area_size, area_unit,year, availability | |
| Фид VK Транспортные средства | VK | Продажа новых и б/у автомобилей, грузовиков лодок, прицепов и т.п. | id, title, link, brand, model, image_link, price, description, state_of_vehicle, year, exterior_color, mileage.value, mileage.unit, body_style, vin, condition, sale_price, min_price, max_price, custom_label, availability, vehicle_type, location.address, location.country, location.region, location.locality, metro.name | |
| Фид VK Услуги | VK | Любые услуги | id, title, price, link, image_link, brand, worker_type, description, location.address, location.locality, location.region, location.country, metro.name, min_price, max_price, product_type, rating, reviews_count, custom_label | |
| Фид VK авиарейсы | VK | Продажа авиабилетов | origin_city, destination_city, description, image.url, url, price, id, origin_airport, destination_airport, sale_price, custom_label_0 |
Как быстро собрать все URL для парсинга
Когда вы будете парсить для фидов свои сайты, вам понадобится быстро собрать все ссылки на нужные страницы. Есть несколько вариантов как это сделать:
- Если страниц не много, можно просто копировать ссылки на них правой кнопкой мыши или из адресной строки (Спасибо КЭП).
- Найти карту своего сайта, если такая есть. Как правило, путь к ней прописан в файле robots.txt (он по адресу vashsite.ru/robots.txt). Так же его можно найти в Яндекс Вебмастере в разделе «Индексирование» → «Файлы Sitemap». В этом файле обычно собраны по категориям все ссылки на страницы сайта.
- Спарсить ссылки в Google таблицу из любого меню сайта или из каталога товаров точно так же, как мы парсили весь остальной контент. К примеру, на моем сайте это можно сделать так:
=importxml("https://zurov.ru/product_cat/web-dev/";"//ul[@class='sidebar-menu']/li/a/@href") - спарсит ссылки в элементах (li) списка (ul) с классом sidebar-menu (это список бокового меню сайта)
=importxml("https://zurov.ru/product/";"//a[@class='product-card__pic']/@href") - спарсит ссылки на все товары из их карточек в каталоге



